Transformer
Abstract
之前的序列到序列模型需要CNN或RNN。本文提出了新的网络架构,免除了递归和卷积。具有并行性,且训练时间更少。在两个机器翻译任务上具有更好的性能。
Introducntion
RNN,LSTM,GRU已经在序列建模取得了最好的性能。从那之后,大量的女里继续推送了循环语言模型和Seq2Seq模型的发展。在RNN中存在两个约束:(1)并行化难。上一步的输出是下一步的输入,这种固有的顺序性质影响了训练的并行化。(2)长程依赖问题。
注意力机制不考虑输入、输出序列的距离,通常用于序列建模。有时结合RNN一起建模。
本文提出Transformer,完全基于注意力机制来得到输入和输出之间的全局依赖。避免了循环,可以并行化计算,在八块P100GPU 上训练十二小时后在翻译任务上达到了SOTA。
Background
减少序列的计算会使用到卷积,对于所有的输入输出位置计算隐层表示。这些模型中将两个任意输入或输出位置的信号关联起来所需的操作数随着位置之间的距离增加,这使得学习远距离位置之间的依赖关系变得更加困难。在Transformer中,任意两个位置间的操作数为固定常量。
自注意力有时又叫内部注意力,是一种关联序列不同位置的注意力机制,目的是得到序列的表示。自注意力成功地应用在多种任务中,包括:阅读理解,摘要总结,文本征集和学习句子表示。
端到端记忆网络基于循环注意力机制,不是序列对齐的循环,已经被证明在简单语言问答和语言建模中表现良好。
据我们所致,Transformer是第一个完全依赖自注意力计算输入输出表示的模型,没有使用RNN和CNN。接下来,描述Transformer,自注意力,和本模型相较于其他模型的有点。
Model Architecture
大部分的神经序列传导模型具有编码器-解码器架构。本模型中,编码器输入为序列$(x_1,…,x_n)$,输出为序列$z=(z_1,…,z_n)$。对于解码器,给定z,得到输出$(y_1,…,y_n)$。在每一步中,模型都是自回归的,生成下一步都会将之前的生成的作为输入。
Transformer遵循这种结构,对于编码器和解码器使用堆叠注意力和逐点全连接层。如下图所示:
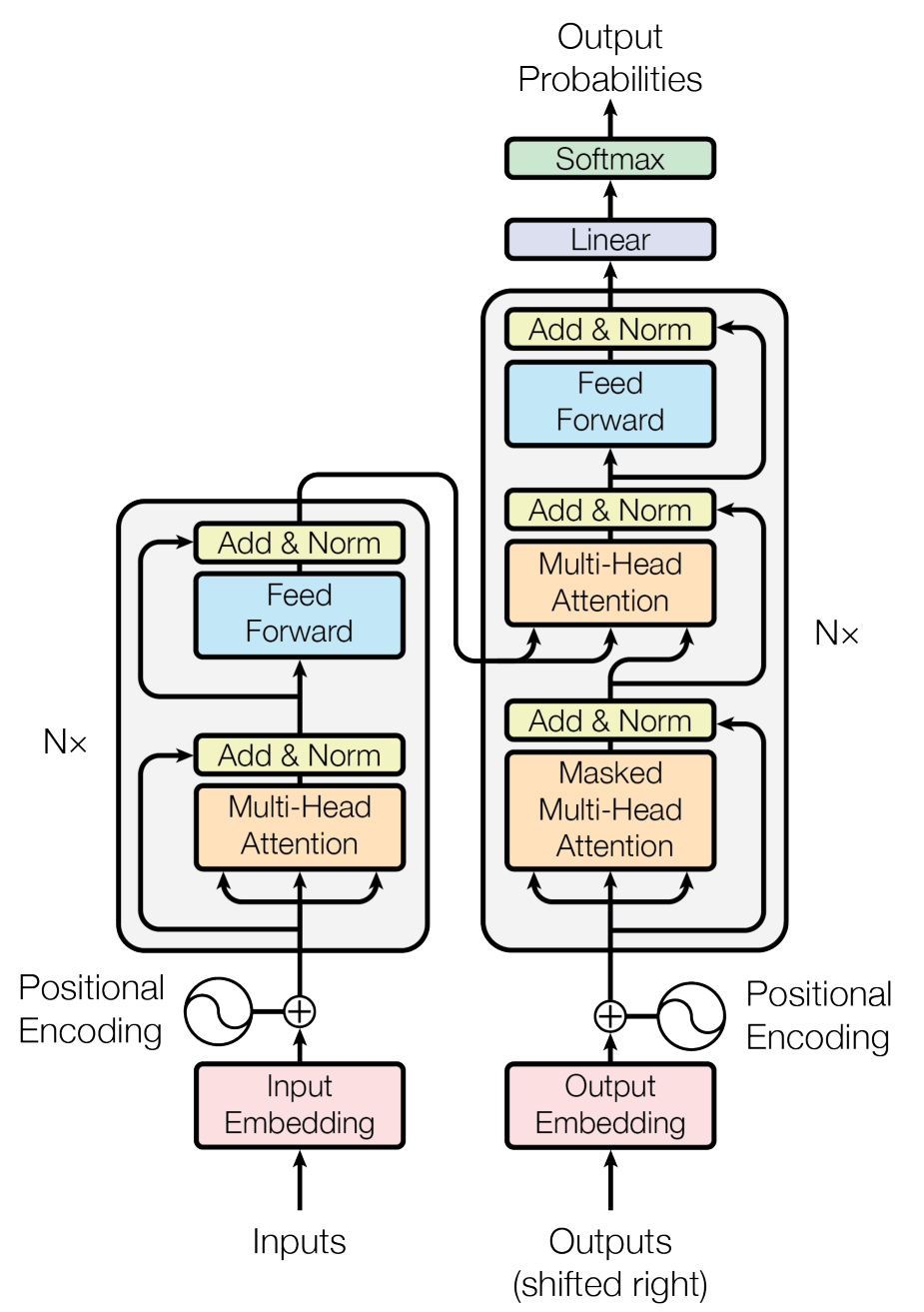
编码器和解码器堆叠
编码器
编码器由$N=6$个相同的层组成,每个层由多头注意力和全连接前馈神经网络组成。两个子层之间使用残差连接,接着使用Layer Normalization。也就是说,每个子层的输出是$LayerNorm(x+Sublayer(x))$,其中$SubLayer(x)$是子层函数本身。为了方便残差的链接,模型中所有的子层,和嵌入层的输出维度都为512,$d_{model}=512$.
解码器
解码器同样由$N=6$个相同的层组成,除了像编码器中的两个子层外,解码器中加入了第三个子层用于对于堆叠编码器的输出做多头注意力。与编码器相似,解码器中每个子层之间使用残差连接,之后使用Layer Normalization。同时修改了自注意力层,防止当前位置对后面位置的注意。使用mask,加上输出嵌入便宜,保证位置$i$的预测只能依赖小于位置$i$的已知输出。
注意力
注意力机制是将query和一系列key-value对映射为output,其中query,key,value,output都是向量。output为value的加权求和,每个value的权重使用兼容性函数(点积)计算。
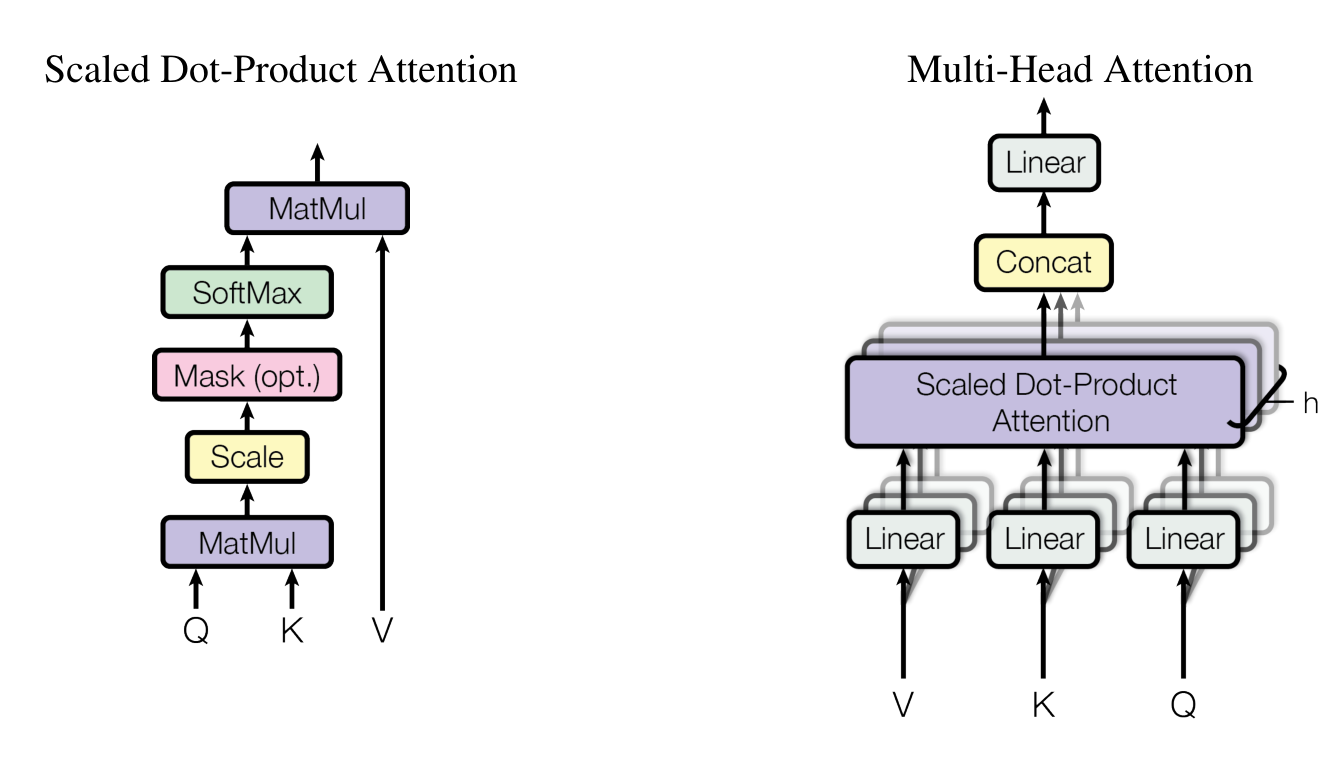 上图左为:缩放点积注意力,右图为多头注意力(可并行)
上图左为:缩放点积注意力,右图为多头注意力(可并行)
缩放点积注意力
缩放点积的输入为:query,keys,values.其中query和key是$d_k$维,value是$d_v$维。用query和所有的key 计算点积并除$\sqrt{d_k}$,然后用softmax函数得到values的权重。(在知乎看到别的大佬的理解,注意力机制的本质为加权。把注意力求解过程看为搜集资料的过程,比如你要写一篇论文-attention,在浏览器中输入的论文题目-query,浏览器返回一系列带有标题key的网页,每个网页都有内容value。写论文的过程就是对每个网页value的进行加权求和的过程,权重通过q,k,v计算得到)
在实际中,并不是每个query单独计算,而是多个query组成query矩阵$Q$并行计算。同样,多个key和value组成矩阵$K$和$V$.输出的计算方式为:
常见的注意力打分函数分为两种:(1) Additive attention (Bahdanau attention https://arxiv.org/pdf/1409.0473.pdf). 注意力打分函数使用一个具有一个隐藏层的前馈神经网络(2) dot-product attention(本文). 点积注意力打分函数和本文类似使用点积,本文中使用$\frac{1}{\sqrt{d_k}}$
对点积进行缩放。两种打分函数理论上复杂度相似,但是在实际中点积可以使用矩阵乘法实现,计算时间更快,空间也更省。
当$d_k$的值较小时,两种注意力机制的效果类似。当$d_k$的值较大时,additive attention的表现好于不缩放的dot product。猜想:$d_k$较大,点积在数量级上会更大,将softmax 函数推到退到梯度极小的区域,为了抵消这种影响,我们使用$\sqrt{d_k}$进行缩放。缩小方差,使得梯度分布更合理
多头注意力
相比于单一地计算,$d_{model}$维的keys,values,queries,我们发现q,k,v线性映射$h$次分别得到$d_k$,$d_k$,$d_v$维。然后再连接在一起,再一次映射得到最终的值。
多头注意力使得模型联合注意来自不同位置的不同子空间表示信息。
其中,映射使用参数矩阵
在本文中多头的注意力$h=8$,对于每个头$d_k=d_v=d_{model}/h=64$.由于每个头的维度降低,所以总的计算成本与全维度的单头注意力相似。
注意力的应用
- Encoder-Decoder Attention 层:query来自先前的Decoder层,key和value来自Encoder的输出。Decoder中的每个位置可以注意输入序列中的所有位置。
- Encoder中包括自注意力层。自注意力层中所有的q,k,v来自前一层Encoder的输出。Encoder中每个位置可以可以注意到前一层Encoder的所有位置。
- 类似的,decoder中的Self-attention层允许解码器中的每个位置Attend当前解码位置和它前面的所有位置。这里需要屏蔽解码器中向左的信息流以保持自回归属性。具体的实现方式是在缩放后的点积Attention中,屏蔽(设为负无穷)Softmax的输入中所有对应着非法连接的Value。
逐位置前馈网络
编码器和解码器中除了注意力子层还包括了全连接前馈网络,分别作用于每个位置。包括两个线性变换和一个ReLU激活函数。
尽管线性变换在不同位置是相同的,但是在层与层之间使用不同的参数。相当于在层与层之间使用了两个卷积核大小为1的卷积。输入和输出的维度是$d_{model}=512$,内层维度是$d_{ff}=2048$
Embeddings and Softmax
与其他序列转换模型一样,我们使用已经预学习的嵌入将输入token和输出token转换为$d_{model}$维向量。同时,我们使用预训练的线性变换和softmax函数将解码器的输出预测为下一个token的概率。在本模型中,我们在两个embedding和pre-softmax线性变换中共享相同的权值矩阵。
Positional Encoding
由于模型没有卷积和循环,为了让模型充分利用序列的顺序信息,我们加入了一些序列token的相对和绝对位置信息。在Encoder和Decoder的底部加入了Positional Encoding,维度和Embedding相同都是$d_{model}$维,所以二者可以相加。本文使用了不同频率的余弦和正弦函数
其中,$pos$是位置,$i$是维度,postional encoding 的每一个维度对应一个正弦。波长从2π到$10000·2 \pi$。对于是因为对于任意固定的偏移量k,$PE_{pos+k}$的线性函数。
Why Self-Attention

n是序列长度,d是序列表示的维度,k是卷积核大小,r是限制注意力的邻居大小
三个方向进行对比:
(1)每层总的计算复杂度。(2)可以被并行化的数量。由所需的最小顺序操作数来衡量。最小并行化单位(3)网络中长距离依赖的路径长度。长距离依赖是序列传导任务的关键。
Training
Training Data and Batching
Training Data:
(1)英语-德语:WMT2014 English-German 数据集,共计450万个句子对。句子使用字节编码,共享37000个token。
(2)英语-法语:WMT2014 English-French 数据集,共计360万个句子,共享32000个token。
Batching:
句子长度相似的组合在一起,每个训练集的batch包括25000个数据和2500个标签。
Hardware and Schedule
我们使用8张NVIDIA P100显卡训练模型。对于本文中的base模型的超参数6.2介绍,每个训练步骤0.4秒,总计10000步约12小时。本文中的大模型,每步约1秒,训练300000步,约3.5天。
Optimizer
使用Adam优化器,$\beta_1=0.9,\beta_2=0.98,\epsilon=10^{-9}$.学习率公式如下:
对于第一个warmup_steps训练步骤线性增加学习率,然后按步数平方根的反比减少学习率。使用$warmup_steps=4000$
Regularization
在训练时两种方法进行正则化:Residual Dropout ,Label Smoothing
(1)对于当前层的输出,在进行下一层的输入和归一化之前,进行dropout.除此之外,对于embedding和positional encoding进行drop out 。其中$P_{drop}=0.1$.
(2)使用$\epsilon_{ls}=0.1$的标签平滑,这回导致了困惑,因为模型学习更不稳定,但是提高了准确性和BLEU分数。
Results
Machine Translation
英语-德语翻译任务中:Transformer(big)高于当前最好模型2个BLEU,达到了28.4BLEU。使用8个P100显卡训练了3.5天。即使是Transformer(base)已经超过了之前的所有模型,且训练成本仅为其他名的一小部分。
英语-法语翻译任务中,Transformer(big)达到了41的BLEU,超过了之前的所有模型,同时训练成本只有最好模型的1/4。其中$P_{drop}=0.1$
Transformer(base)每十分钟写入一个checkpoint,然后平均最后五个checkpoints。Transformer(big)平均最后20个checkpoint,使用size为4的beam search,length penalty $\alpha=0.6$.在开发集上进行超参数选取,测试时的最大输出长度为输入长度+50.
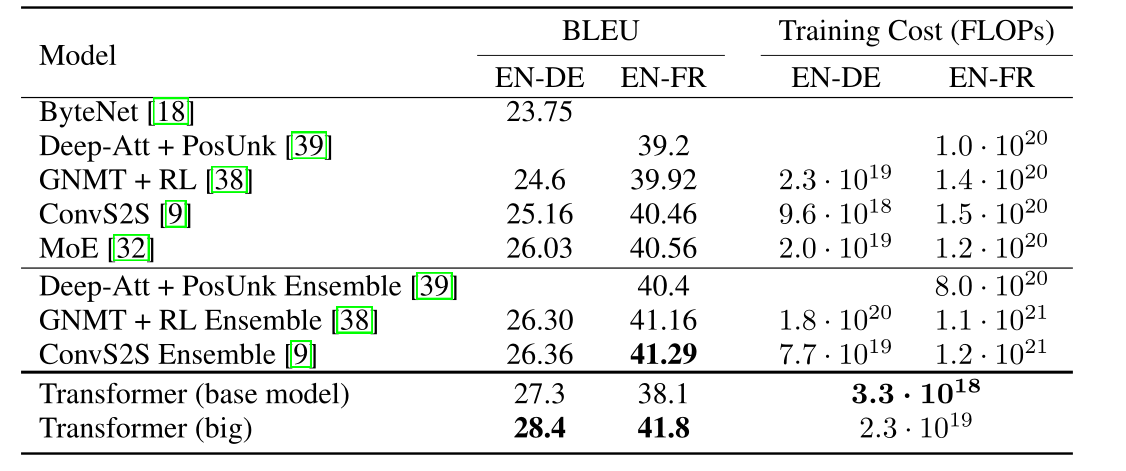
上表总结了transformer模型结果并且和其他模型比对翻译质量和训练成本。
Model Variations
为了评价transformer不同组成部分的重要性,我们控制变量来获得不同参数对性能的改变。使用beam search但是没有使用checkpoint average。
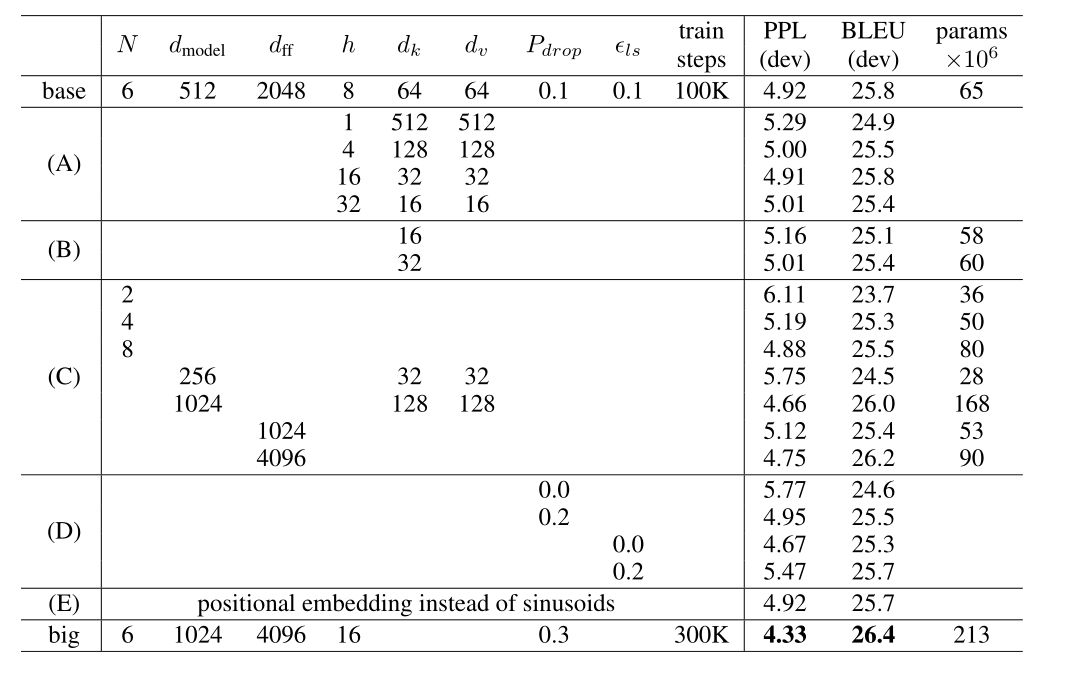
如表中所示,改变注意力头的数量,注意力的key和value的维度。可以看到单头注意力比最好的设置小0.9个BLEU,head过多会使得质量下降。
English Constituency Parsing
为了评估transformer是否可以推广到其他任务,我们进行了英语依存句法分析实验。这个任务具有两个挑战:(1)输出结果受限于强的结构化限制。(2)输出比输入长。除此之外,RNN seq2seq模型也没能在小数据集上达到最佳性能。
我们在WSJ数据集上训练4层transformer,$d_{model}=1024$。我们也在半监督的设置下训练,使用大约170万条句子的BerkleyParser语料库。在只有WSJ的设置中使用16k个词汇,在半监督的设置中使用32k个词汇量。
在开发集上进行少量的实验来选择dropout、attention、residual、learning rate和beam size,其他参数与英-德基础翻译模型保持不变。在测试时,最大输出长度为输入长度+300。在WSJ和半监督实验上使用$beam size=21, $ $\alpha=0.3$.
Conclusion
本文提出Transformer,是第一个完全基于注意力的序列传导模型,使用多头注意力替代了encoder-decoder结构中常用的循环层。
对于翻译任务,Transformer的训练快于CNN和RNN。在WMT2014 English-to-German和WMT2014 English-to-French任务上,我们达到了最佳性能。我们的模型甚至由于之前所有模型的组合。
我们对于基于注意力的模型的未来感到兴奋,并计划将其应用到其他任务中。我们计划将Transformer的输入和输出扩展到文本之外的其他模态。同时研究局部受限注意力机制,以有效处理大量的输入和输出,如图像、音频和视频。