组会四
ERNIE-ViL
keypoint
- 从场景图中获得结构化知识来学习视觉语言的联合表示。
- 建立视觉语言的语义联系:对象,对象属性,对象关系。
- 预训练任务:
- Object Prediction
- Atrribute Prediction
- Relationship prediction
- 五个下游任务数据集:VQA,VCR,RefCOCO+,IR,TR尤其是VCR提升3.7%。
contrbutions:
- first introduce structured knowledge
- construct sence graph prediction,cross-modal detailed semantics alignments
- 5 SOTA
当前预训练模型发展的三驾马车
- 模型结构:single-stream, two stream
- 预训练任务: masked language model(MLM), masked region prediction(MRP),Image-Text Matching. 当前随机掩码预测,无法区分普通单词和描述语义的单词,无法捕捉跨模态细粒度语义对齐
- 预训练数据:
- (out of domain)CC,SBU
- (in domain) MSCOCO,Visual-Genome
场景图
- 组成:object ,atrributes of objects, relationship
- 场景图是描述图片和文本详细语义的良好先验,在图像字幕,图片检索,视觉问答,图片生成等任务达到SOTA
Approch
模型结构:
Sentence Embedding: WordPiece Token。word embedding+segment embedding+sequence position embedding。

Image Embedding: region feature+location feature
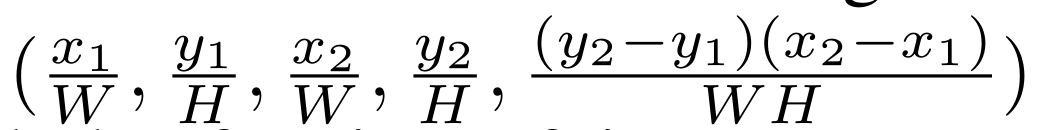
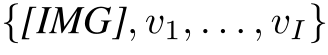
Vision-Language Encoder: two-stream cross-modal Transformer
场景图预测:
- object:场景的基本元素。attribute:例如物体的形状、颜色。relationship:物体之间的空间联系和动作
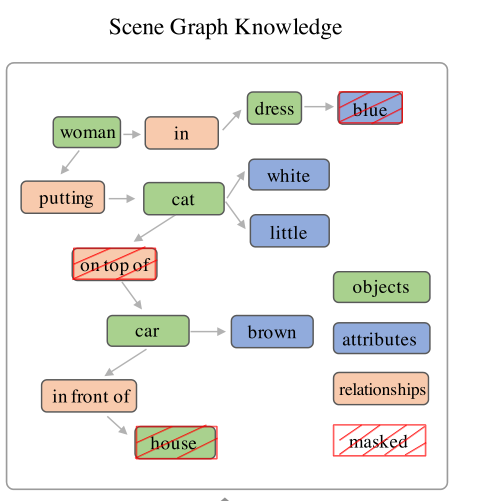

G(w)=
- O(w):object;
- E(w): 三元组,
- K(w):二元组,
- Spice: Semantic propositional image caption evalu-
ation.
Object Prediction:
- 对象是视觉场景的主导元素,在构建语义信息的表征中起着重要作用。预测对象迫使模型在对象级别建立视觉语言连接。
- 场景图中随机选30%进行mask, 选中的O(w),80%进行[mask],10%随机替换,10%保持。对应的文本进行mask。
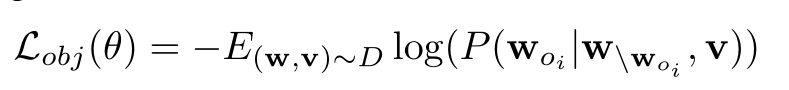
Attribute Prediction:
- 属性表征了视觉对象的特定信息,如对象的颜色或形状,从而在更细粒度的层次上表示视觉场景中的详细信息。
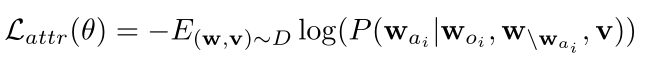
Relation Prediction:
- 关系描述了视觉场景的对象之间的动作(语义)或相对位置(几何),这有助于区分对象相同但关系不同的场景。
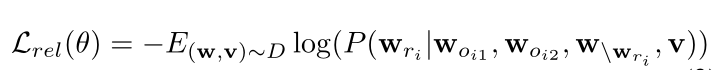
Oscar
- Object-Semantics Aligned Pretraining
- Motivation:当前的视觉-语言预训练简单地将图像特征和文本特征进行拼接,然后用自注意力蛮力学习图像和文本的语义对齐。图像中的显著对象在文本中经常被提及。
- 输入:Triplet(文,tag, 图)-> (w,q,v)
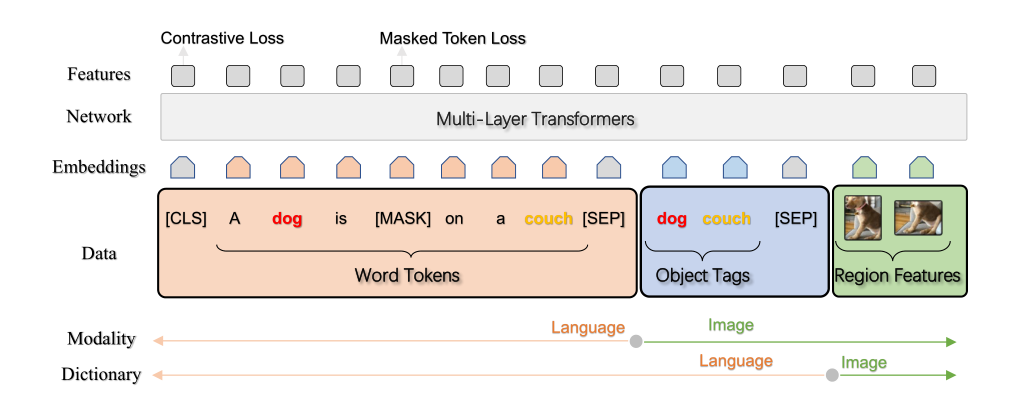
两个预训练任务即两个损失函数。
- Dictionary View——Masked Token Loss::
- 把tag当做文本,[h= (w, q ), v ]. wq看做整体,视为token的集合,mask并且预测
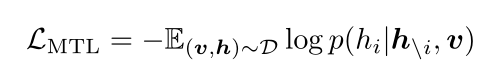
- Modality View——Contrastive Loss:
- 把tag当做图像模态,[ w , h=(q, v) ]. 构建反例:50%的概率替换q(q’, v)。预测-> f(h,w)=1为正例,否则为反例。
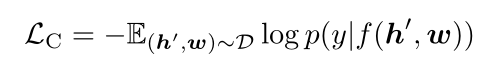
- Dictionary View——Masked Token Loss::
ViLT
- motivation:当前的VLP,图像都依赖于特征提取,基本涉及到目标检测或者卷积结构。这会导致提取特征的计算量超过多模态交互的步骤。
- 区域特征的提取在训练前已经被预先提取,所以学术上经常忽略image embedder较重的缺点,对于数据集外的查询,需要经历一个缓慢的提取过程。
- 最小的VLP模型。减轻加速视觉嵌入。假设VLP中用于模态交互的Transformer也可以像提取文本特征那样来替代卷积提取视觉特征。
- 视觉-语言模型分类:
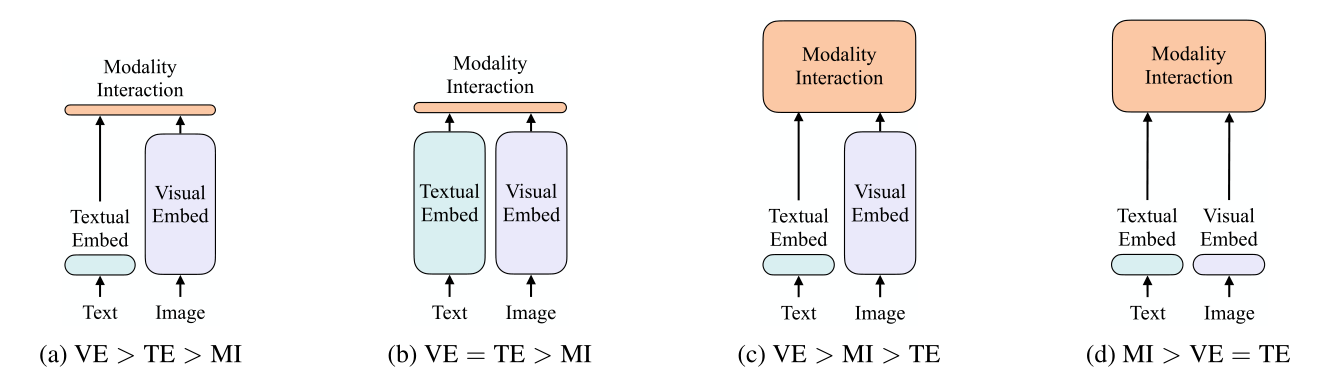
- a: VSE,VSE++,SCAN
- b: CLIP(ResNet, Transformer)
- c: ViLBERT,UNITER (token, faster r-cnn) PixelBERT (token, resnet )
- d:ViLT (token ,patch)
- 模态交互模式:
- single stream——concact
- dual stream——-coatten, 自己的q,另一个模态的k,v
视觉嵌入模式:
Region Feature——-BoundingBox 的featuremap
Grid Feature——-全图的featuremap,pixel级别
Patch Projection——-简单的线性映射。2.4M参数,R50-25M, R101-44M
模型图
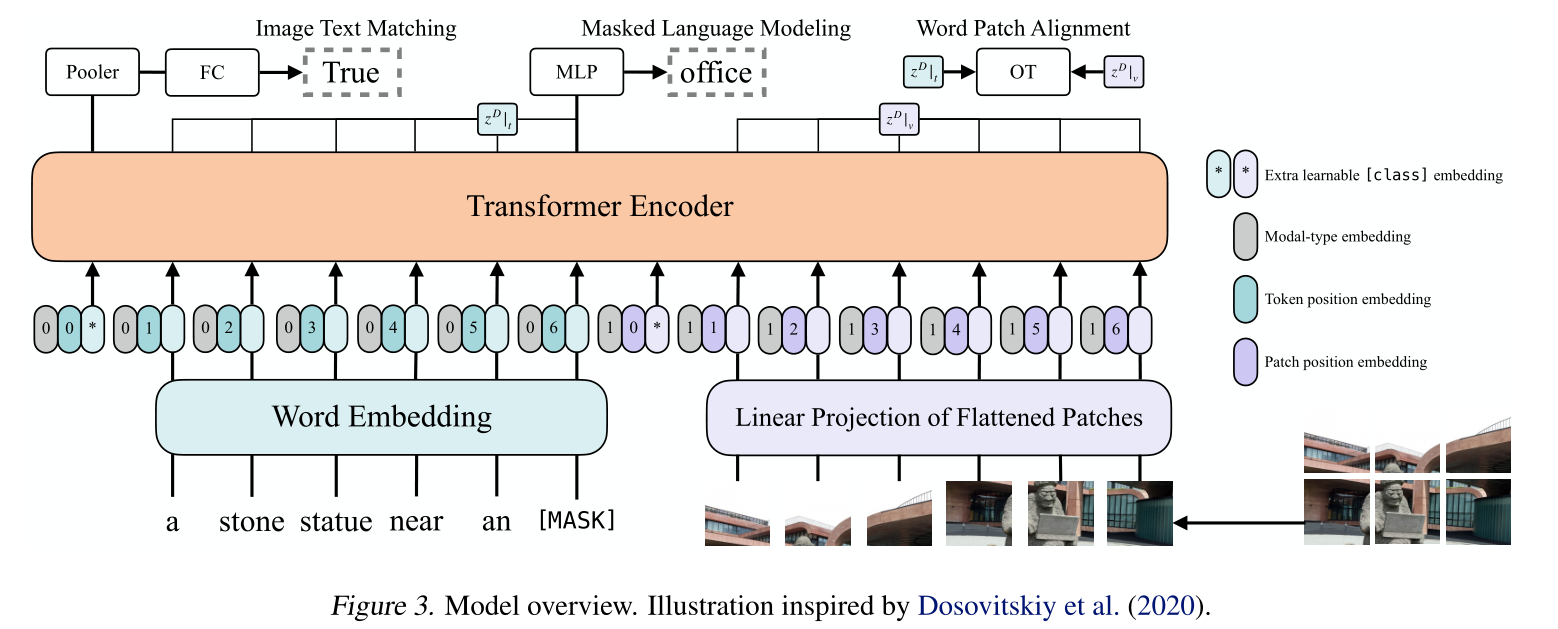
- 预训练的ViT来初始化Transformer
- 文本->tokenize->Word Embedding; 图像->patch->patch projection(visual embedding)
- +position embedding
- concate modal-type embedding
- 预训练任务:
- image text matching(ITM):随机以0.5的概率将文本对应的图片替换成不同的图片,然后对文本标志位对应输出使用一个线性的ITM head将输出feature映射成一个二值logits,用来判断图像文本是否匹配。另外ViLT还设计了一个word patch alignment (WPA)来计算textual subset和visual subset的对齐分数。
- masked language modeling(MLM):MLM的目标是通过文本的上下文信息去预测masked的文本tokens。随机以0.15的概率mask掉tokens,然后文本输出接两层MLP与车mask掉的tokens。
- Whole Word Masking:另外ViLT还使用了whole word masking技巧。whole word masking是将连续的子词tokens进行mask的技巧,应用于BERT和Chinese BERT是有效的。比如将“giraffe”词tokenized成3个部分[“gi”, “##raf”, “##fe”],那么可以mask成[“gi”, “[MASK]”, “##fe”],模型使用[“gi”,“##fe”]来预测mask的“##raf”,而不使用图像信息。