预训练模型综述
[2106.07139] Pre-Trained Models: Past, Present and Future (arxiv.org)
Introduction
深度学习CNN,RNN,GNN,attention近些年广泛应用于各种AI任务中。不同于传统的特征工程,深度学习无需手工设计特征,可以从数据中学习到分布式表示作为数据的特征。由于神经网络有着大量的参数,所以深度学习的训练需要大量的数据,以防止过拟合。然后手动标注数据又非常地耗时耗力。
迁移学习是解决这个问题的里程碑,无需在大量的数据上从头训练,在小样本上便可以解决新的问题。迁移学习是一种双阶段学习框架:(1)从一个或多个源任务中捕获知识。(2)在有限的样本下进行微调。
迁移学习缓解了数据饥渴,很快用在CV中。如,在ImageNet上进行预训练。受益于ImageNet中强大的视觉知识分布,使用少量特定任务数据微调这些预先训练的CNN可以在下游任务中表现良好。
不同于CV的监督学习,NLP领域使用自监督学习,例如mask文本,学习文本中的内在相关性来还原mask文本。这种自监督学习的方法无需标记的文本数据便可以学习文本的表示。
早期将深度学习用于NLP时,会出现梯度的消失或爆炸。因此NLP的预训练使用浅层的网络来捕获单词的语义。如,Word2Vec和GloVe。但是,这些词嵌入是静态的,不适用于多语义的单词。这便催生出了预训练的RNN来学习上下文的词嵌入。但是模型的效果会局限于模型的大小和深度。
Transformer的提出,使得在NLP领域训练深的模型成为了可能。以Transformer为架构,以语言模型为目标,衍生出了GPT和BERT。巨大的参数可以捕获文本的词汇和语法结构等知识。在下游任务上进行微调便能取得的很好的性能。
对预训练模型进行微调,而不是从头学习模型成为了共识。然而,我们并不清楚大量模型参数的本质,即可解释性较差。不同的PTM往往朝着四个重要方向发展:设计有效的架构、利用丰富的上下文、提高计算效率以及进行解释和理论分析。
Background
PTM的发展依赖于迁移学习,经过有监督的预训练发展到现在的自监督预训练。迁移学习旨在从多个源任务中捕获重要知识,然后将这些知识应用到目标任务中。
迁移学习包括两种:特征迁移和参数迁移。特征迁移方法,预训练特征的表示,然后将表示注入到目标任务中。例如word2vec,ELMO。参数迁移遵循一个假设:源任务和目标任务可以共享模型参数或者超参数的先验分布。因此,参数迁移把学习到的知识编码进模型参数中,然后再微调。例如,预训练的CNN,BERT。
AlexNet提出后,一系列深度学习便被提出,这些深度神经模型具有更多的参数和更好的拟合能力。将网络的结构变深可以提高模型性能,但是也会带来梯度消失会爆炸,同时模型性能会到达上限,然后随着网络的深度增加而降低。提高在参数初始化进行归一化,和引入残差结构可以有效解决这些问题。
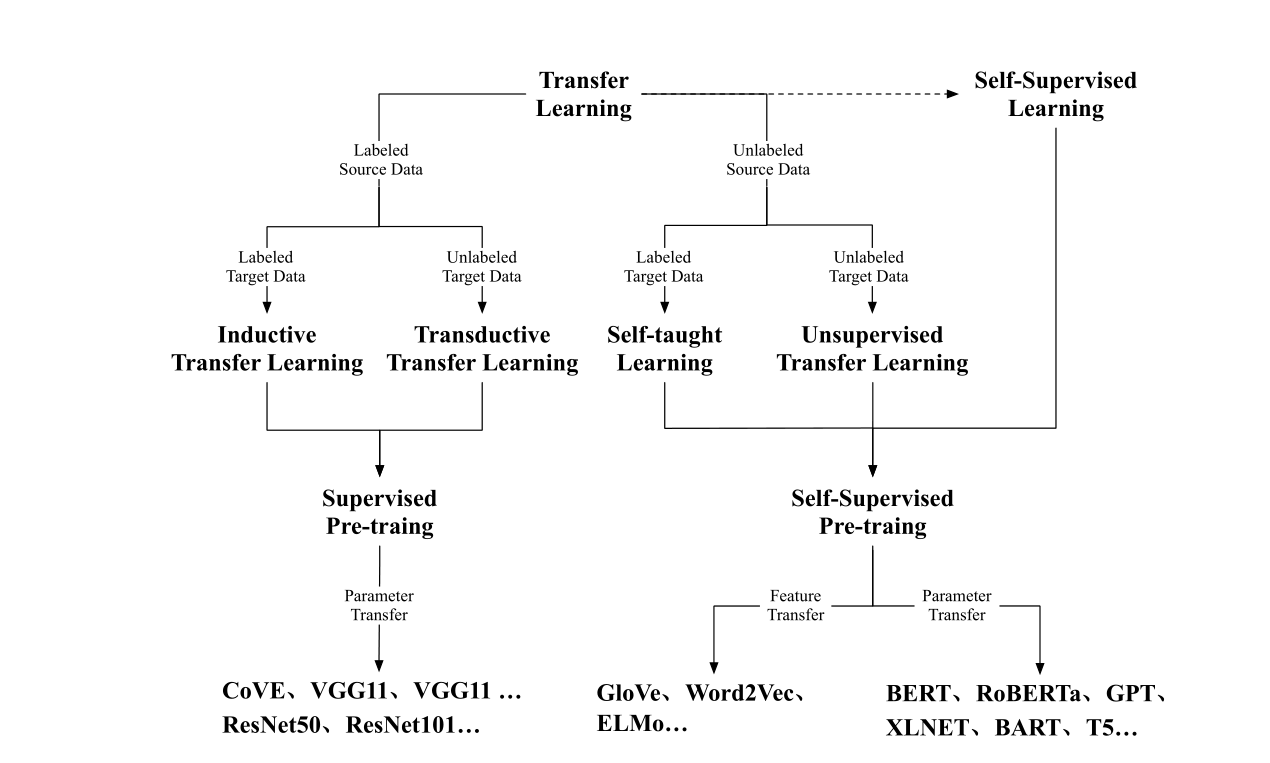
迁移学习可以分为四个子类:Inductive Transfer Learning ,Transductive transfer learning, Self-taught Learning, Unsupervised Transfer Learning.
无监督学习是应用无标签的数据进行学习。自监督学习是无监督学习的分支,利用输入数据本身作为监督信息。无监督学习常用于聚类,异常检测等;自监督学习常用于分类和生成。
Transformer and Representative PTMs
Transformer
在Transformer之前处理文本一直使用RNN,由于RNN具有顺序性,每一时刻按顺序读取单词,并考虑之前单词的隐藏状态,因此很难并行化计算。Transformer是一种自注意力编码器-解码器结构,可以并行化建模输入序列的单词关系。
Transformer的编码阶段:对于给定的单词计算与输入序列其他单词注意力分数。这个注意力分数表示其他单词对于生成给定单词表示的贡献程度。最后通过注意力分数计算其他单词的加权平均来表示给定单词。
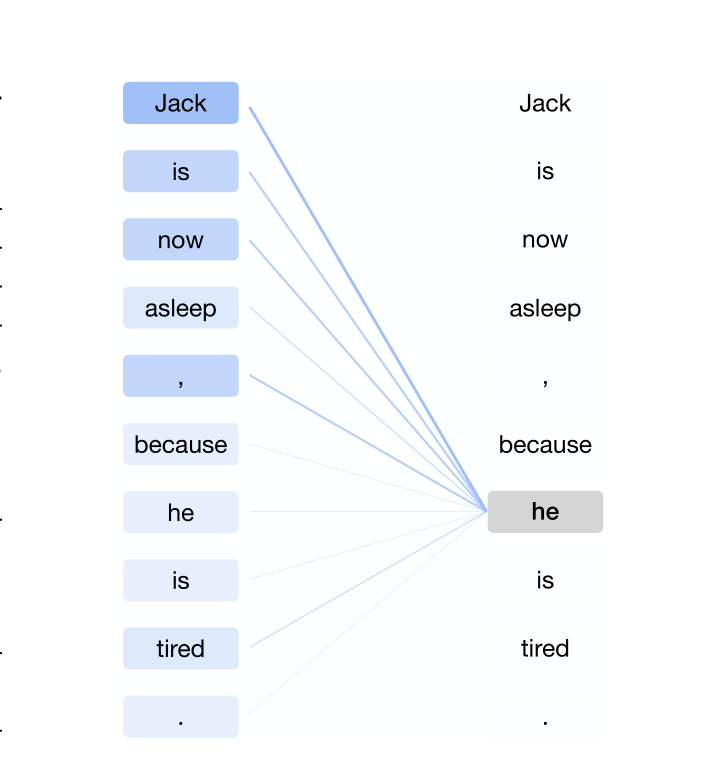
如图所示,单词he的表示由所有单词进行加权求和。在解码阶段,从左到右一次只解码一个表示,解码阶段的每一个表示都参考之前的解码结果。
GPT
第一个结合Transformer和自监督的模型,在几乎所有的自然语言处理任务上都取得了成功包括,自然语言推理、问答、常识推理、语义相似性。
GPT模型是一种自回归模型。优化给定前文条件下,当前词的条件概率。Transformer的decoder结构。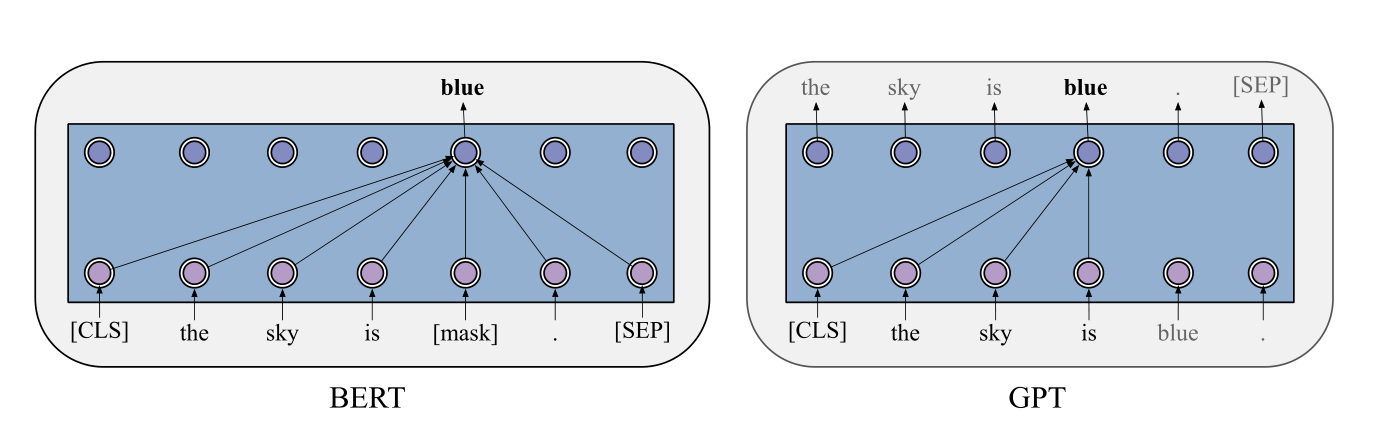
如图是BERT和GPT的区别,GPT对之前的单词进行自注意力。微调阶段,输入数据得到GPT最后一层的表示,并利用特定任务的标签,以在下游任务上进行微调。
BERT
BERT的出现极大地促进了PTM的发展。采用Bidirectional Encoder Representation Transformer,是一种自编码语言模型。预训练阶段,进行两个任务:MLM+NSP。MLM即随机mask单词,让模型进行还原。BERT可以学习到双向单词表示。NSP预测当前的句子和下一个句子是否为顺应关系。因此可以学习到句子表示。经过预训练,BERT可以获得用于下游任务的鲁棒参数。通过用下游任务的数据修改输入和输出,BERT可以针对任何NLP任务进行微调。BERT可以通过输入一个句子或句子对来有效地处理这些应用。对于输入,它的模式是两个用特殊标记[SEP]连接的句子,可以表示:(1)释义中的句子对,(2)蕴涵中的假设-前提对,(3)问答中的问题-通道对,以及(4)用于文本分类或序列标记的单个句子。对于输出,BERT将为每个标记生成一个标记级表示,可用于处理序列标记或问题回答,特殊标记[CLS]可被送入一个额外的层进行分类。
Others
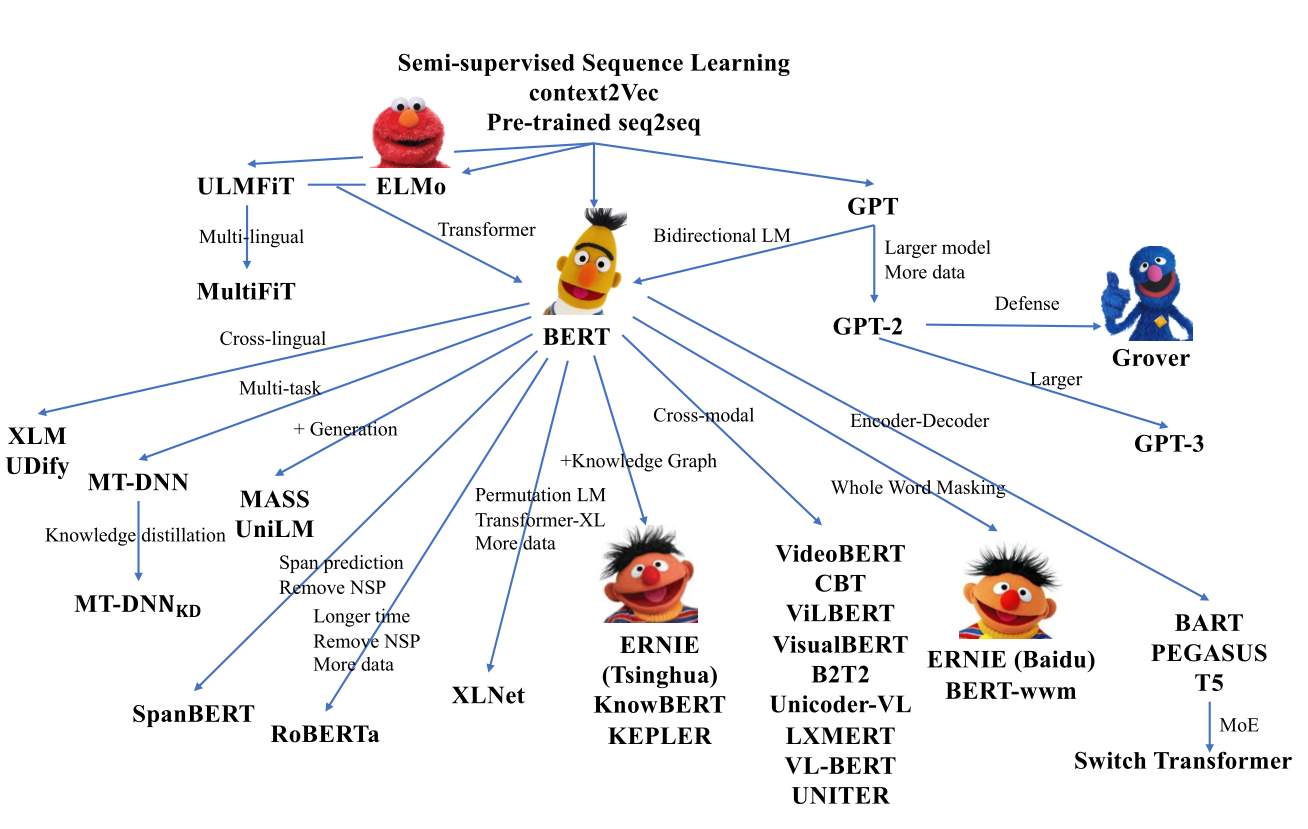
RoBERTa:(1)去除NSP任务(2)更多数据,更大batch size,更多训练次数。(3)更长的训练句子。(4)动态改变掩码模式。同时之处NSP任务对于BERT训练没有作用。
ALBERT,减少参数。(1)输入单词的嵌入矩阵分解为两个较小的矩阵。(2)强制所有的Transformer层之间共享参数。(3)句序预测代替NSP任务
Designing Effective Architectures
统一序列建模+认知启发架构
统一序列建模
自然语言下游任务通常分为三类:
(1)自然语言理解:语法分析,句法分析,问答,推理。
(2)开放文本生成:对话生成,故事生成
(3)非开放文本生成:机器翻译,摘要汇总
结合自回归和自编码建模:
- PLM
- XLNet=GPT单向生成+BERT双向理解在预训练中替换token顺序,用自回归预测
- MPNet改进了XLNet预训练不知道句子长度,下游任务指导句子长度的问题
- 多任务训练
- UniLM:联合训练不同的语言模型,单向,双向,seq2seq。
- GLM:给定变长的mask跨度,模型自己生成mask掉的token,在所有类型任务上达到最优的模型
使用通用的Encoder-Decoder
在GLM之前BERT或GPT都不能解决变长填空问题。BERT的[mask]数量会泄露信息,GPT只能在序列的末尾生成。
MASS引入 masked-prediction到encoder-decoder架构,但没有解决变长填空问题。
T5:一个[MASK] 取mask变长的token然后decoder还原
BART:对源序列进行阶段、删除、替换、打乱、mask
挑战:会带来更多的参数,在自然语言理解的任务上表现不佳
认知启发架构
人类水平的智力远比仅仅理解不同事物之间的联系要复杂得多。在追求人类水平的智能时,理解我们认知功能的宏观结构至关重要,包括决策、逻辑推理、反事实推理和工作记忆。
可维护的工作记忆
Transformer的问题是固定的窗口大小,和长度平方的复杂度。这阻碍了在长文档理解中的应用。在实际中,人类没有表现出远程注意力机制,而是不仅记忆和组织同时也会遗忘。类似于LSTM。
- Transformer-XL:引入片段级别递归和相对位置编码,然后知识隐式地模拟了工作记忆。
- CogQA:在多跳阅读中维护一个认知图。由两个系统组成:(1)系统一基于预训练模型。固定窗口大小。(2)系统二基于图神经网络。
- CogLTX:利用MemRecall语言模型来选择应该保留在工作记忆中的句子,并利用另一个模型进行回答或分类。
可持续的长期记忆
Transformer能够记忆,有研究将Transformer的前馈神经网络替换为key-value记忆网络,发现效果很好,某种程度上说前馈神经网络相当于记忆网络。
- REALM:为Transformer构建一个可持续的外部记忆,作者逐句张量化整个维基百科,检索相关句子作为上下文进行掩蔽预训练。对于给定数量的训练步骤,张量化的维基百科被异步更新。
- RAG:将mask预训练扩展到自回归生成。
Utilizing Multi-Source Data
多语言,多模态,知识增强的PTM。
多语言预训练
与训练几个单语言模型相比,用几种语言训练一个模型可以获得更好的性能。
BERT之前有两种方式学习多语言表示:(1)多语言对一起训练多语言LSTM实现多语言翻译。(2)学习语言的不可知约束,如WGAN将语言表示解耦为语言特定和语言无关的表示。多语言任务可以分为理解任务(分类)和生成任务(翻译)
非平行语料库:
- mBERT:(MMLM )多语言掩码语言建模:很好地学习到跨语言表示
- XLM-R:支持100多种语言,更大的预料,带来了更好的性能
平行语料库:
- XLM:利用双语对进行翻译语言建模(TLM)任务,把两个语义匹配的句子合并成一个随机同时mask两个部分,鼓励模型将两个语言的表示对齐在一起。
- CLWR:cross-lingual word recovery。 CLWR利用目标语言嵌入通过利用注意机制来表示源语言嵌入,其目标是恢复源语言嵌入。该任务使模型能够学习不同语言之间的单词级对齐。
- CLPC:cross-lingual paraphrase classification。CLPC将对齐的句子视为正对,将未对齐的句子样本视为负对,以执行句子级分类,让模型预测输入对是否对齐。可以学习到不同语言之间的句子级别对齐。
- ALM:自动从平行句子中生成代码切换序列,并对其执行,这迫使模型仅基于其他语言的上下文进行预测。
- InfoXLM:从信息论的角度分析MMLM和TLM,鼓励模型在对比学习的框架下从不对齐的负例中区分出对齐句子。
- HICT:扩展了使用对比学习来学习句子级别和单词级别的跨语言表示
- ERNIE-M:回译掩码语言模型,并扩展了平行语料库的规模
多语言预训练生成模型
- MASS: 将MLM掩码语言建模扩展到语言生成。随机mask一段tokens然后用自回归的方法进行还原。
- mBART :通过添加特殊符号扩展降噪自编码器(DAE)以支持多种语言
- XNLG:跨语言自编码器,与DAE不同,XAE的编码输入和解码输出是不同的语言,类似于机器翻译。此外,XNLG以两阶段的方式优化参数。它在第一阶段用MLM和TLM任务训练编码器。然后,它在第二阶段使用DAE和XAE任务修复编码器并训练解码器。通过这种方法对所有参数进行了很好的预训练,填补了MLM预训练和自回归解码微调之间的空白。
多模态预训练
视频和图像属于vision,文本和语音属于language。难点是将非文本信息融合进BERT
- ViLBERT:分别处理文本和图像信息,然后传入两个 encoder,然后使用 Transformer 层得到联合 attention 结果
- 首次提出视觉语言预训练
- 双流输入
- 三个预训练任务:MLM(掩码语言模型)+SIA(句子图像对齐)+MRC(掩码区域分类)
- 五个下游任务:VQA(visual question answering),VCR(visual commonsense expression),GRE (grouding referring expressions),ITR(image-text retrieval),ZSIR(zero-shot image-text retrieval)
- LXMERT:
- 比ViLBERT多两个预训练任务(MRFR)masked feature regression,VQA
- 三个下游任务:VQA,graph question answering (GQA) ,natural language for visual reasoning(NLVR2)
- VisualBERT:极小的代价扩展了BERT,一种简单高效的baseline
- 单流输入
- 预训练任务:MLM+IA(图文是否匹配)
- 四个下游任务:VCR+NLVR2+VQA+ITIR
- Uicoder-VL
- offsite visual detector 移动到端到端版本中,将 Transformer 的图像标记设计为边界框和对象标签特征的总和
- 三个预训练任务:MLM,SIA(图文是否匹配),MOC(masked object classification )
- 三个下游任务:IR,ZSIR,VCR
- VLBERT
- 两个预训练任务:MLM+MOC
- 发现SIA会降低模型性能
- 三个下游任务:VQA,VCR, GRE
- B2T2
- 解决VQA
- 两个预训练任务:MLM+SIA
- VLP
- 解决VQA,Image caption
- encoder 和decoder共享参数
- 预训练任务:bidirectional masked language prediction(BMLP),sequence to sequence masked language prediction(s2sMLP)
- UITER
- 学习图像和文本之间的统一表征
- 预训练任务:MLM,SIA,MRC,MRFR
- 下游任务:VQA,IR,VCR,NLVR2,REC,VE(visual entailment)
- ImageBERT:
- 弱监督收集大规模图文数据
- 预训练任务:MLM,SIA,MOC,MRFR
- 下游任务:ITIR
- X-GPT:
- BERT多模态下理解任务上结果优异,但是不能直接用于生成任务。
- 预训练任务:image-conditioned masked language modeling (IMLM), image-conditioned denoising autoencoding (IDA), and text-conditioned image feature generation (TIFG)
- 下游任务:Image-caption
- Oscar:
- 引入图像的目标检测标签作为对齐图像和文本的锚点
- 动机:图像的目标检测的标签在文本中通常被提及
- 下游任务:ITIR,IC,novel object captioning(NOC),VQA ,GCQ,NLVR2
- DALLE
- 第一个文本到图像的零样本预训练模型,弥补了文本描述和图像生成之间的差距,尤其是在组合不同物体方面具有出色的能力。
- CogView
- 引入sandwitch transformer和稀疏注意力从而提高准确率和训练稳定性
- 超越了DDALLE
- CLIP&WENLAN
- 探索为 V&L 预训练扩大网络规模数据并取得巨大成功
- 大规模分布式预训练
知识增强预训练
引入外部知识例如知识图谱,领域知识,与练数据的额外注释,可以成为统计建模的良好先验。
结构化知识-知识图谱
- 引入实体-关系 embedding或者他们的对齐
- wang2021:基于维基百科实体的描述,整合语言模型损失和知识嵌入损失来获取知识增强表征
- 一些工作直接将知识图谱的路径甚至是子图与对齐的文本建模,以此保留更多的结构化知识
- 由于将(实体,关系)与原文本对齐时,在数据预处理会出现噪声。一些工作直接将序列化的知识转变为结构化的文本,让模型自己去学习知识-文本对齐
- OAG-BERT:融合多种开放学术图谱中的结构化知识
融合非结构化知识,特定领域或任务的数据
- 继续训练得到领域或任务模型
- 吸收领域或任务标注数据
可解释融合
- 在下游任务中基于检索方法使用结构化知识
- 使用适配器在不同的带标注的知识来源上训练,以便区分知识来自哪里